© Nature/TSP
Informationstechnik: Die Shakespeare-DNS
Wissenschaftler entwickeln einen Code, um Erbgut als unverwüstlichen Datenspeicher zu nutzen. Erste Tests mit den Sonetten des englischen Dichters waren bereits erfolgreich.
Nicht nur Archivare zittern, wenn Dokumente verwittern. Mit dem Berg an gespeicherten Daten wächst allseits die Befürchtung, dass die kostbaren Informationen mit der Zeit erodieren – CD-Roms, Magnetbänder oder Festplatten zum Beispiel halten nur Jahre, allenfalls Jahrzehnte. Forscher erproben deshalb einen Datenspeicher, der sich seit Milliarden von Jahren bewährt hat: das fadenförmige Erbmolekül Desoxyribonukleinsäure, DNS. Es ist nicht nur problemlos tausende Jahre haltbar, sondern verbraucht auch extrem wenig Speicherplatz. Ein internationales Forscherteam hat nun eine neue Methode entwickelt, um Information zuverlässig in kurzen DNS-Schnipseln zu speichern.
Die DNS besteht aus molekularen Bausteinen, den Nukleotiden. Die Nukleotide sind in ihr wie Perlen auf einer Schnur aufgereiht, wobei jedes Nukleotid eine von vier Basen enthält: Adenin, Thymin, Cytosin und Guanin. Die Abfolge dieser biochemischen Buchstaben, ihre Sequenz, enthält die Bauanleitung der Proteine (Eiweißmoleküle), der Bausteine und molekularen „Handwerker“ allen Lebens. In der Natur wird der DNS-Strang durch einen zweiten „komplementären“ Faden ergänzt, wobei immer Adenin und Thymin sowie Cytosin und Guanin aneinanderkoppeln.
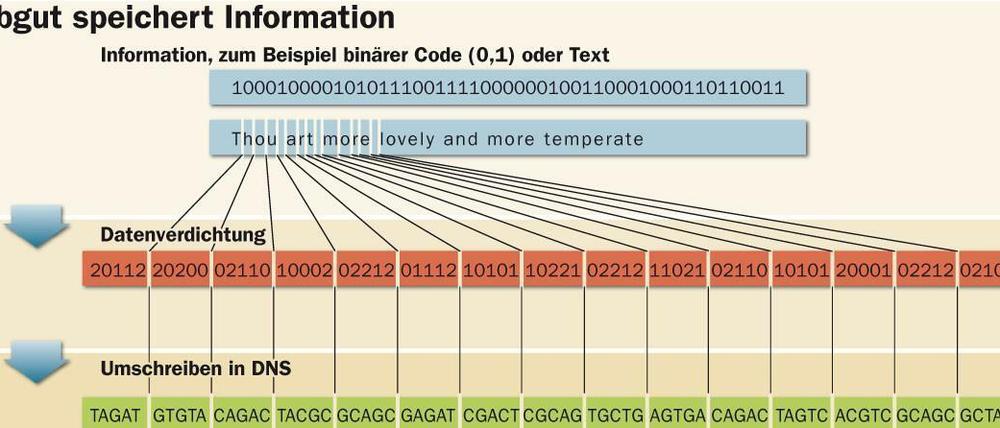
Diese vier Basen-Buchstaben können auch unabhängig von ihren biologischen Aufgaben in der Zelle als Informationsträger dienen, vergleichbar den Bits des binären Computercodes. Einer von vier Basen-Buchstaben kann dabei theoretisch für zwei Bits stehen, er kodiert entweder für 1:1, für 1:0, für 0:1 oder für 0:0.
Ein großes Problem beim Nutzen von DNS als Speichermedium ist die Tatsache, dass es bislang nur möglich ist, kurze Abschnitte von Erbinformation künstlich herzustellen. Außerdem treten beim Schreiben und Lesen Fehler auf, vor allem, wenn sich zwei Buchstaben wiederholen. Beide Schwierigkeiten konnten Nick Goldman vom Europäischen Bioinformatik-Institut im britischen Hinxton und sein Team meistern, wie die Forscher im Fachblatt „Nature“ berichten.
„Wir wussten, dass wir einen Code erzeugen mussten, der nur kurze Abschnitte von DNS benutzt, und das auf eine Weise, bei der nicht zwei Mal die gleichen Buchstaben nacheinander auftauchen“, berichtet Goldman laut einer Pressemitteilung des Europäischen Informatik-Instituts. „Also beschlossen wir, die Information in viele überlappende Fragmente aufzubrechen, die zudem in beide Richtungen (komplementär) liefen. Außerdem erzeugten wir ein Kodierungsmuster, das ohne Wiederholungen auskommt.“
Mit der Umsetzung beauftragt wurde das Biotechnik-Unternehmen „Agilent“ im kalifornischen Santa Clara. Fünf verschiedenartige, aus dem Internet heruntergeladene Dateien musste Agilent in DNS umschreiben, darunter ein kurzer Abschnitt aus Martin Luther Kings epochemachender Rede „I Have a Dream“ (mp3-Format), alle Shakespeare-Sonette (txt-Format) und eine wissenschaftliche Studie (PDF-Datei), alles in allem 5,2 Megabit. Die Informationen wurden in insgesamt 153 335 DNS-Schnipseln abgelegt, jeder 117 Nukleotide lang, die Originaldateien waren damit 1300-fach abgedeckt. Die Informations-Fragmente wurden dann milliardenfach kopiert, gefriergetrocknet und aus Kalifornien zum Dechiffrieren auf die Reise nach Europa geschickt. „Das Ergebnis sah aus wie ein winziges Häufchen Staub“, erinnert sich Agilent-Mitarbeiterin Emily Leproust.
Das Entziffern der Botschaften aus den kurzen DNS-Abschnitten am Europäischen Bioinformatik-Institut klappte fehlerfrei, berichten die Wissenschaftler. „Die Begutachtung ergab, dass jede unserer ursprünglichen Computerdateien mit 100-prozentiger Genauigkeit rekonstruiert wurde“, schreiben die Forscher. „Wir haben einen Code geschaffen, der Fehler toleriert und unter richtigen Bedingungen 10 000 Jahre oder länger haltbar ist“, sagte Nick Goldman. „So lange wie jemand weiß, wie der Code funktioniert, wird man dazu in der Lage sein, ihn zu lesen. Vorausgesetzt, man hat eine Maschine, die DNS entziffern kann.“
Die Forscher wollen nun darangehen, den Chiffriercode weiter zu verbessern und die praktische Umsetzung auszuloten. Noch ist die Methode sehr aufwendig und teuer und nicht für den täglichen Gebrauch geeignet. Denkbar ist jedoch, sie irgendwann für das Speichern von gewaltigen Datenmengen aus naturwissenschaftlichen Experimenten zu nutzen, etwa von denen des Large Hadron Colliders am Genfer Forschungszentrum Cern oder von astronomischen oder medizinischen Untersuchungen. Mehr als ein Eimerchen DNS wird man dazu bestimmt nicht benötigen.
- showPaywall:
- false
- isSubscriber:
- false
- isPaid:
- showPaywallPiano:
- false